When he wrote The Making of a Fly, biologist Peter Lawrence probably did not expect his investigation into developmental genetics to rival the Magna Carta. But in 2011, copies of this book were listed for sale at Amazon for $23.6 million, a price that exceeded a recent sale price of the Great Charter of Liberties (the Magna Carta).
The reason is that prices for The Making of a Fly were being set by two competing algorithms, creating a feedback loop of escalating prices. The first seller’s bot would look at the lowest available price and set his at 27 percent above that. Then the second seller’s bot would look at the highest price and strategically undercut by selling his copy at 0.2 percent less. In most cases, this strategy would work for both sellers. But neither seller anticipated this possibility, and pricing bots don’t have the common sense to recognize when the feedback loop has gone off the rails.
This episode, while hilarious, is a cautionary tale. We are daily edging toward a world in which vital decisions are made through algorithmic processes. Sometimes these algorithms are simple, as in the case above. But the exponential acceleration of the use of machine learning in decision-making means we need to start asking very important ethical questions surrounding algorithmic decision-making.
Machine learning is a tough topic because the details of how machines learn can seem incredibly obscure. Simply put, machine learning is about taking as much data as possible and telling a computer to find patterns within that data. Once a pattern is found, the computer develops an equation wherein we can give it a new point of input and the computer will predict a result.
Let’s make that a little more concrete. A classic machine-learning problem involves breast cancer data. We feed in the imaging data on breast cancer scans. From a biopsy, we look at cell texture, area, symmetry, smoothness, radius, and so on. We “train” our program by giving it 70 percent of that data. It makes a guess about what combination of metrics will accurately predict breast cancer. Then we give it the last 30 percent of that data, and it checks itself to see how accurate it was. Let’s say it’s 90-percent accurate. Now it’s ready for us to feed it new data from the patient who came in yesterday, and it can guess, with 90-percent accuracy, if that patient has breast cancer.
This is a generous example of the utility of machine learning. Machines are excellent at teasing out examples from known data on topics that provide easily measured information. But things get murkier when we branch out into topics that don’t provide convenient, clean data.
In 2016, ProPublica published a devastating critique of a program called COMPAS that claimed to output the risk of a convict committing future crimes. They found that the algorithm used to predict re-offense rates skewed to predict higher risk scores for black individuals and lower risk scores for white individuals.
There were some claims of racism within the company or among the developers of this program, but the most likely scenario is that it was impossible to know exactly how this algorithm came to its risk score. It could very well be that the machine-learning process determined that people of color are arrested at higher rates and used that to predict that people of color are more likely to have higher rates of arrest in the future. The algorithm takes a shameful existing reality and makes no moral judgments on it, but simply extrapolates it in the form of a prediction.
Machine learning used this way has no guiding principle. We can shovel terabytes of data into a system, and there’s still a chance it can go off the rails if there isn’t a person with an ounce of common sense constantly supervising, reviewing, and critiquing the results of the decision-making. And we’re not always able to anticipate how an algorithm will achieve unexpected results. Machine-learning methods can create a “black box” result: we can push data in and see the results, but we don’t know how we got from point A to point B.
Algorithms don’t have common sense. They can’t look at the data and furrow their brow, say “That’s awfully weird,” and ask why. They have their parameters, and if a parameter isn’t included in the system, the machine will barrel ahead without restraint or caution. Given the speed at which these programs make their decisions, this process can spiral in unpredictable and dangerous ways.
—
There is something miraculous in humans that machines will always lack. We don’t just see the world as it is; we see it as it ought to be. This is the core message of C. S. Lewis’ classic book Mere Christianity. Lewis says that an innate part of all of us rebels against the injustices and wrongs of this world because we have within ourselves a spark of the divine that nudges us toward the world as it should be.
Artificial intelligence can’t see the world as it should be; it excels at recognizing the world as it exists. And certain applications of machine learning and artificial intelligence have proven incredibly controversial.
When Amazon built a machine-learning system to help in identifying and hiring the most productive candidates, the system ended up simply filtering women out of the candidate pool. Charges of bias were lodged against the system developers, who ended up scrapping the program. In all of this, no one publicly posed the question, “What if the system preferred men because men are more productive than women?”
I’m making some cynical assumptions about the inputs of the system, but let’s say the system is looking for candidates who might excel in Amazon’s famously aggressive work environment. It might prioritize candidates who work longer hours, forego paid time off, prefer an all-work lifestyle over a work-life balance, relentlessly seek promotion and advancement, or are unlikely to leave the job for family reasons.
In all these metrics, men as a group surpass women. If these are the metrics you’re feeding into your algorithm, it might very well say, “You know what? Let’s immediately narrow the hiring pool by 50 percent and then optimize within that group.” We immediately recognize this as bias, but the algorithm does not. It’s just trying to optimize the metrics we’ve handed to it. We asked an algorithm for productivity, and it gave that to us good and hard. We need to be sure we’re prepared to confront reality as it is, or we’re going to discover that a machine does not much care for our vision of how things should be. It can only see what we show to it, and it will strive endlessly to incrementally achieve whatever goal has been set in the metrics.
There’s a delightful academic paper titled The Surprising Creativity of Digital Evolution from the 2018 Artificial Life Conference that should be our defining reference point when we contemplate machine learning. The paper catalogues the absurd ways an algorithm tries to optimize to achieve its given task.
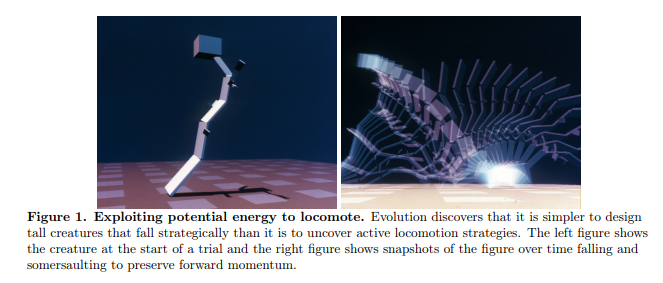
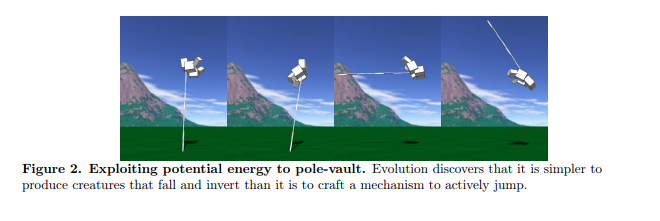
Using a method of machine learning known as reinforcement learning, iterative AI programs were given a task with a metric and instructed to optimize for that metrics. Directed to travel quickly, a simulation evolved to turn itself into a tower and fall over, moving incredibly fast before it slammed itself into the ground. Directed to jump as high as possible (height being the highest point of their structure), simulated robots built themselves to be very tall. When the researcher redefined the definition of “jump” to be “the height of your lowest point,” the bots evolved to have a very long, thin leg, which they then kicked out from under themselves.
Directed to sort a list of numbers as fast as possible, an algorithm learned that if it deleted the list, everything was perfectly sorted.
These are silly examples, but the reality of the matter is that, when directed to optimize a specific metric and given unsupervised authority to change the structure of a given system, machine- learning algorithms can hack any system we give them. We may decide to use AI to determine the best policies for a hospital, but we should carefully investigate its recommendations. If the algorithm is optimized for efficiency, it may discover that the best way to pool money for newborn care is to deny care to the elderly with high-risk cancer. A newborn has high utility, the elderly have low utility, and cancer care is expensive.
Handing vital decision-making to an algorithm could result in a system in which the elderly are not simply denied care but also denied the truth of their condition. The cheapest, most “effective” path would be to simply lie to them, tell them they don’t have cancer, and let them die. Dead people are incredibly cheap.
Artificial intelligence and machine learning have enormous potential to tease our existing models of reality. But we cannot abdicate our decision-making to these algorithms. We can’t use them to inform our decisions and then fall back on the excuse that the responsibility ultimately rests with the algorithm or the developer or scientist who developed it. Converting this messy world and all its inconsistencies into clean data does not make the world clean. It threatens to blind us to the value of the immeasurable.